







FPGA上数字识别的二值化神经网络
背景
神经网络是基于大脑神经网络的机器学习模型。一系列节点以“层”排列,它们通过操作和权重相互连接。该模型已经证明在图像分类任务中是成功的,其目前具有许多应用,从自动驾驶车辆到面部识别。标准CNN可以具有浮点权重和特征映射 - 这些需要大量的存储器资源和计算能力来实现必要的乘法器等。
二进制神经网络利用二值化特征图和权重,大大减少了所需的存储量和计算资源,并且可以在资源受限的系统(如FPGA)上以硬件形式合成它们。我们实现的网络基于使用Tensorflow机器学习库在Python中实现的软件模型。Python代码由康奈尔大学博士生Ritchie Zhao提供。Verilog代码在硬件中实现用于构建软件模型的各种层和功能。该系统旨在对数字进行分类,并使用MNIST数据集的子集来训练模型,并产生大约40%的测试精度。这可以通过使用非二值化特征映射并实现诸如批量规范化之类的附加功能来改进。然而,
Verilog模型用于执行推理任务,但不训练它用于计算的权重。相反,使用的权重由Python实现生成,并在Verilog模型中进行硬编码。当神经网络用于分类时,训练权重是耗时的并且不是实时完成的。因此,我们选择将模型集中在分类任务上,并使用预训练权重进行计算。我们最初计划使用HPS来传递FPGA使用的权重; 但是,这导致使用了太多逻辑单元,并且设计不适合设备。
高级设计
数学概述:
计算不同输出特征图所涉及的数学主要限于乘法和加法运算。由于我们设计中的权重是二进制值,因此可以用三元运算符替换乘法运算,三元运算符确定在“乘以”1或-1(0的权重被视为-1)后是否必须加或减值。这大大减少了实现设计所需的DSP模块数量。通过在输入特征映射上“滑动”滤波器来执行卷积操作。重叠索引相互相乘并相加,以形成相应输出索引处的值。通过确定二值化的值的符号并相应地将输出值分配给-1或1来实现二值化。虽然真正的二值化涉及将输出转换为1或0而不是1或-1,但此网络所需的计算使得转换为1或-1更有效。对于本报告的其余部分,对二值化的引用是指将数字转换为1或-1,而不是1或0.池化操作包括检查给定值集合中的最大值并将输出分配给此最大值。下图描绘了所有这些过程。
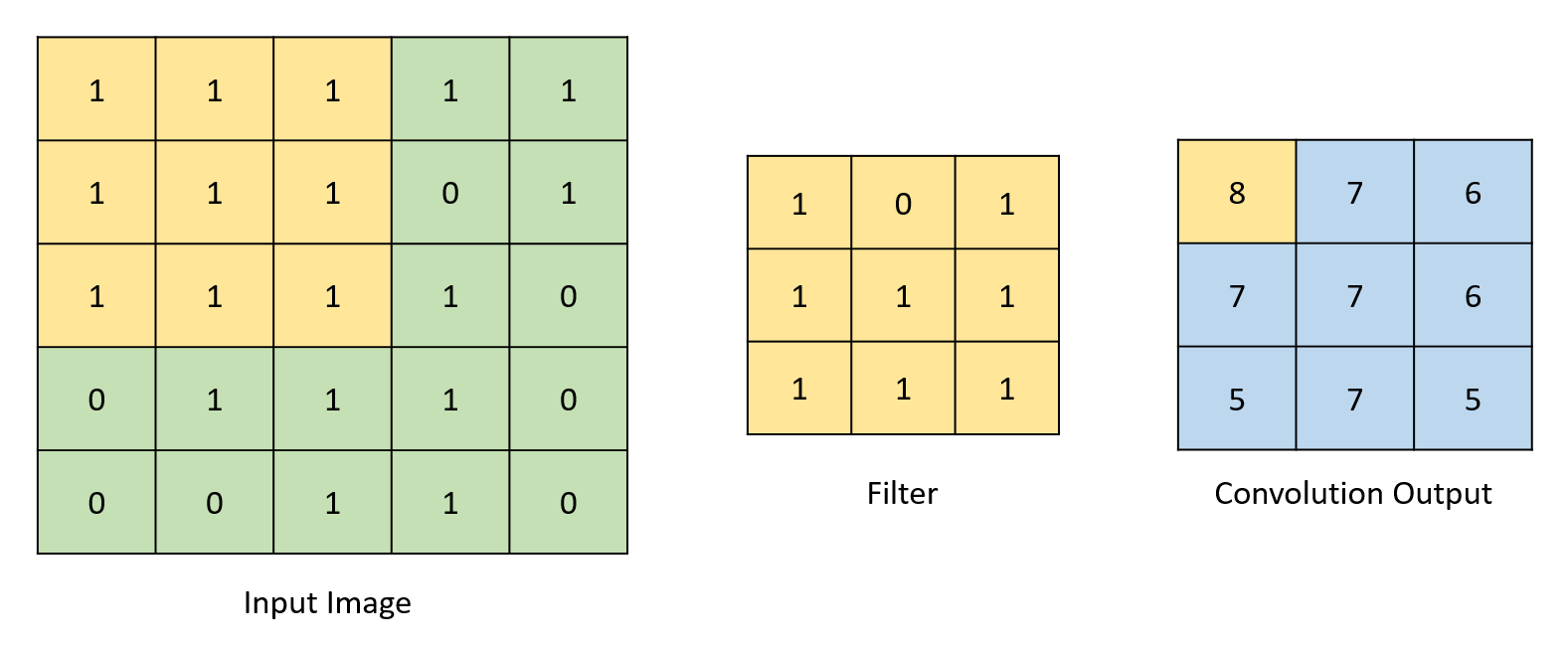
图1:卷积示例
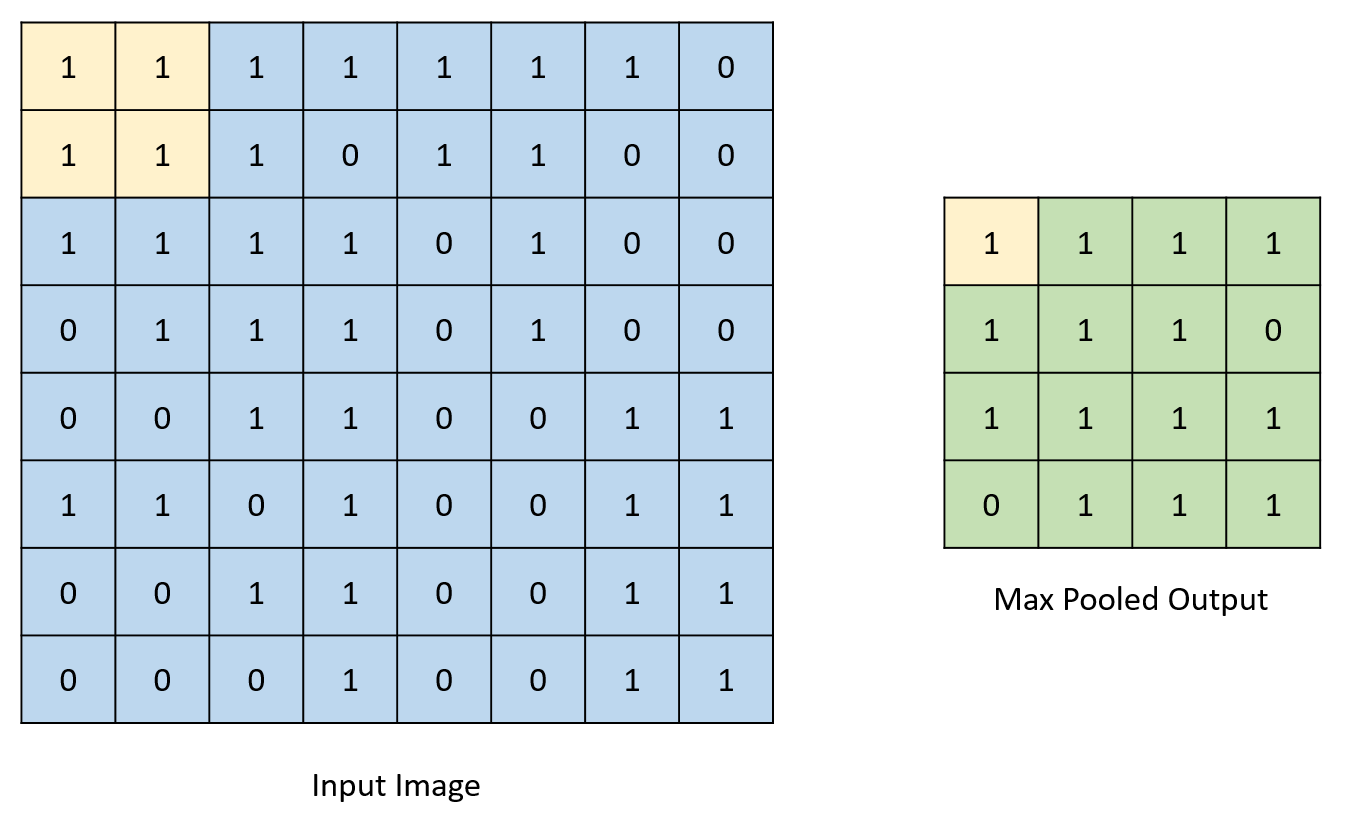
图2:池示例
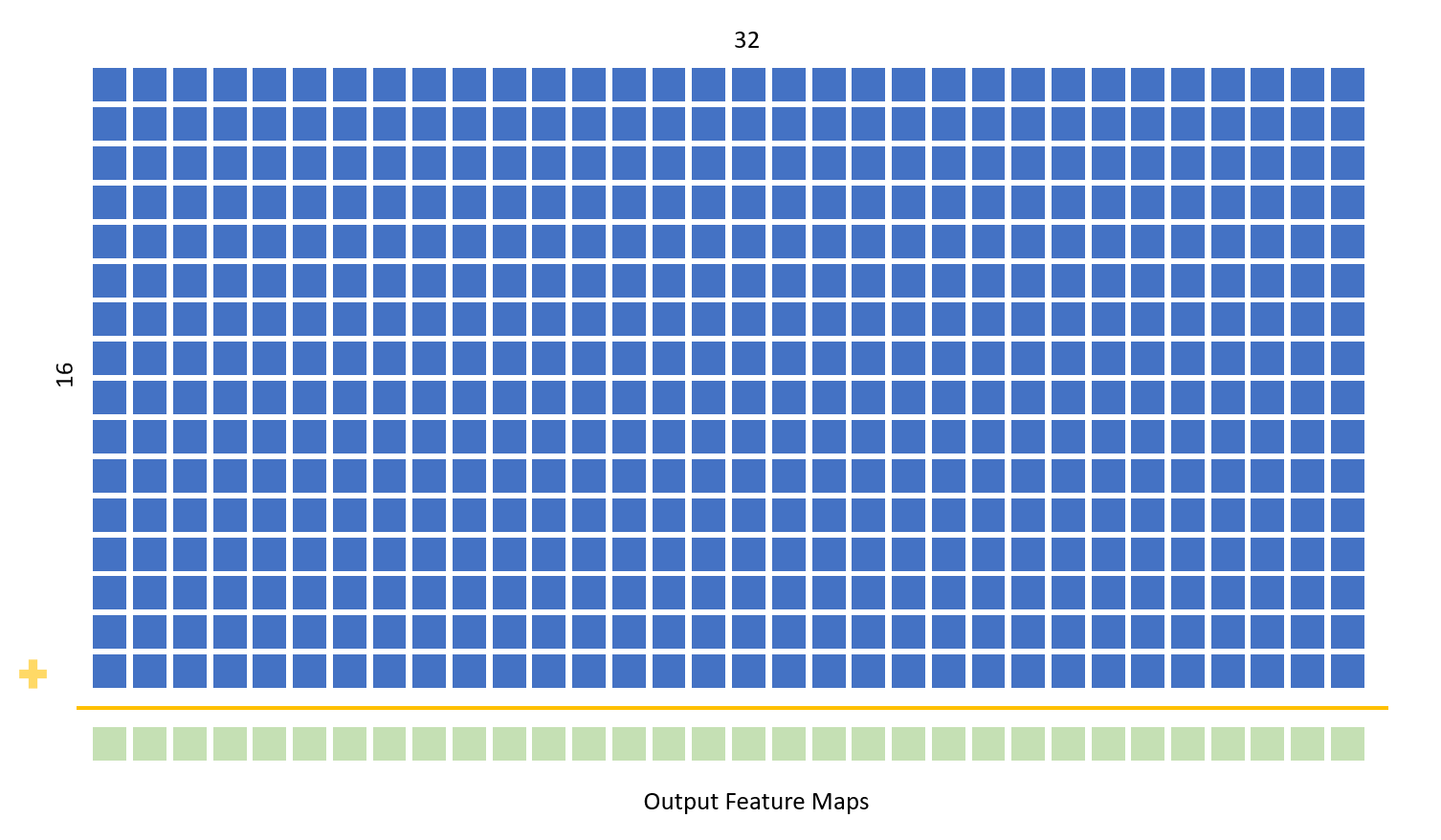
图3:二值化示例
总体概述:
二元神经网络由两个卷积层,两个汇集层和两个完全连接的层组成。输入图像是7×7两位黑白图像。图像在底部和右侧以-1s填充,以产生8×8的图像,该图像被送入网中。第一个卷积层将输入图像与16个3乘3的滤波器进行卷积,以产生16个8乘8的输出映射,这些映射被二进制化以仅包含1和-1。然后合并这16个映射以形成16×4×4个输出映射,然后将其馈送到第二卷积层。第二卷积层包含512×3×3个滤波器。每个图像与32个独特的滤波器进行卷积,以产生32个4乘4输出特征映射。然后将它们二进制化并合并以将它们变成2乘2输出映射,这些映射被传递到完全连接的层。第一个完全连接的层将输入的32 2乘2特征映射平展为一个128条目数组。然后将该阵列与128乘32滤波器阵列进行矩阵乘法,以产生大小为32的输出阵列。然后将该输出阵列二进制化并在最终完全连接的层中乘以32×10滤波器矩阵以产生十个入口阵列。该数组中的每个条目对应于输入图像是与该数组的索引对应的数字的图像的概率。例如,数组中的第0个条目表示输入图像为0的可能性。如果数组中的第0个条目在数组中具有最高值,则BNN将推断输入为数字0。然后将该阵列与128乘32滤波器阵列进行矩阵乘法,以产生大小为32的输出阵列。然后将该输出阵列二进制化并在最终完全连接的层中乘以32×10滤波器矩阵以产生十个入口阵列。该数组中的每个条目对应于输入图像是与该数组的索引对应的数字的图像的概率。例如,数组中的第0个条目表示输入图像为0的可能性。如果数组中的第0个条目在数组中具有最高值,则BNN将推断输入为数字0。然后将该阵列与128乘32滤波器阵列进行矩阵乘法,以产生大小为32的输出阵列。然后将该输出阵列二进制化并在最终完全连接的层中乘以32×10滤波器矩阵以产生十个入口阵列。该数组中的每个条目对应于输入图像是与该数组的索引对应的数字的图像的概率。例如,数组中的第0个条目表示输入图像为0的可能性。如果数组中的第0个条目在数组中具有最高值,则BNN将推断输入为数字0。该数组中的每个条目对应于输入图像是与该数组的索引对应的数字的图像的概率。例如,数组中的第0个条目表示输入图像为0的可能性。如果数组中的第0个条目在数组中具有最高值,则BNN将推断输入为数字0。该数组中的每个条目对应于输入图像是与该数组的索引对应的数字的图像的概率。例如,数组中的第0个条目表示输入图像为0的可能性。如果数组中的第0个条目在数组中具有最高值,则BNN将推断输入为数字0。
所有特征映射和权重数组都存储在寄存器中,并且使用三元运算符实现卷积和矩阵乘法。使用DSP模块会导致设计所需的乘数不足。两位大小的特征映射和1位权重阵列可以最大限度地减少存储需求,从而无需使用M10K块等内存单元。每层的所有重量都在Verilog中进行了硬编码。我们最初计划使用PIO端口将HPS馈送到权重中; 然而,这导致使用FPGA中可用的更多ALM。
硬件设计
输入图像
来自对应于十个数字中的每一个的MNIST测试集的十个输入图像在FPGA上的Verilog中被硬编码。FPGA从HPS接收输入选择信号,该信号用于在作为输入的各种图像中进行选择并馈送到二值化卷积网络中以生成数字预测输出。来自MNIST测试集的输入图像被平均合并到1比特灰度级的7乘7尺寸矩阵。我们对每个条目使用2位,因为输入被二进制化为1或-1,其中2'b01表示黑色像素,2'b11表示白色像素。然后我们用-1s填充底行和右列以形成8乘8矩阵,然后将图像输入到第一卷积层。这使矩阵的尺寸均匀,更容易在其他层中使用。
VGA /摄像机
我们最初的计划是使用NTSC摄像头捕捉实时图像或手写数字作为输入并实时进行数字分类。我们从Avalon Bus Master到HPS页面上的Bruce视频代码开始,它通过Qsys中的Video_In_Subsystem模块将视频输入存储到片上SRAM,并且有一个总线主控器将像素从SRAM复制到双端口SDRAM,其中然后,VGA控制器模块在VGA屏幕上显示SDRAM数据。我们玩了代码和Qsys视频子系统模块。我们能够将8位RGB颜色转换为2位灰度,如下图所示,使用Video_In_Clipper和Video_In_Scaler Qsys模块将输入大小从320x240修剪为224x224,然后使用合并池在HPS上创建7x7图像。后来,我们意识到这个计划不可行,因为我们在FPGA上运行了ALM,我们最常用它来构建实际的二值化神经网络。因此,我们选择对来自FPGA上的MNIST数据集的一些现有输入图像进行硬编码,并通过选择信号发送以从中选择各种信号。
![]()
图4:224x224 2位灰度至7x7 1位灰度
卷积层一
第一个卷积层使用16 3乘3的滤波器,每个条目的大小为1位。输入图像是8×8矩阵,条目大小为1比特,并与每个滤波器进行卷积,以生成大小为8×8的16个输出特征图。通过填充所有大小保持与输入图像相同的大小输入图像的边用零,使其成为10×10矩阵。当与3乘3矩阵卷积时,这导致8乘8矩阵。
通过使用三元运算符来确定滤波器中的位是1还是0,从而是否将输入fmap中的值加到或减去临时和来实现卷积。为了节省空间,我们使用1比特权重(1或0)和三元运算符而不是两个比特权重来表示1和-1。临时总和存储在临时特征输出中。对于输出特征映射中的每个条目重复这一过程,并且对于16个3乘3的过滤器中的每一个并行进行。计算所有临时和值后,这些符号位用于为输出要素图中的相应条目指定+1或-1。基本上,如果它是正数且大于0,我们将临时总和分配给+1。其他,我们将它分配给-1。请注意,我们使用此实现将-1分配给临时总和0。该层使用两个组合始终块实现,一个实现填充,另一个计算卷积。每个块包含嵌套的for循环,允许并行计算所有临时总和。在代码的主体中,生成循环用于实现16个这样的卷积单元,以允许并行计算16个输出特征映射中的每一个。
汇集图层
网中有两个最大汇集层,每个卷积层后有一个汇总层。池化层将输出要素图缩小了两倍。第一个汇集层将8个8个特征映射转换为4个乘4个映射,而第二个汇集层将4个4个特征映射转换为2乘2个映射。这是通过获取四个值的平方中的最大值并将该值指定为一个条目来代替输出特征映射中的所有四个值来完成的,从而减小了大小。两个层都使用for循环实现,以生成硬件以同时处理输入要素图中的所有元素。
卷积层二
第二个卷积层的实现方式与第一个卷积层的实现方式大致相同。两个组合始终块用于填充图像并计算来自卷积的临时总和,然后将其存储在输出特征映射中。与第一个卷积块不同,此处的输出不会立即二值化,因为必须首先计算部分和。16个特征映射中的每一个与32个唯一滤波器的卷积为每个输入特征映射创建32个输出特征映射。然后将这32个输出求和并二值化以创建32个最终输出映射。在主代码体中,嵌套在生成块内的循环用于并行实现所有卷积。
部分总和
部分和层采用由第二卷积层计算的16 * 32 4乘4的特征映射,并且将对应于每个输入16特征映射的32个映射汇总到该层。使用32 4乘4累积临时和数组计算部分和。状态机用于首先在第一状态中将数组中的所有值初始化为0,并且在下一状态中迭代16×32×4×4阵列中的16行,该数组被传递到层中。嵌套for循环用于并行计算32乘4乘4的部分和 - 在此状态下16个时钟周期之后,已计算出部分和并且状态机移动到下一状态。这里,将部分和二值化并分配给32×4×4输出特征图,该特征图被传递到第二池化层。
图5:部分总和
第一个完全连接的层
完全连接的层采用由第二汇集层输出的32×2×2矩阵并使其变平以形成一维128长度阵列。将其乘以128乘32矩阵以形成长度为32的阵列。该层也使用状态机和长度为32的临时和数组来实现。在第一个状态中,临时和值全部初始化为0.在下一个状态中,三元运算符用于确定权重矩阵中的值是否为a 1或0,并且分别从临时总和中加上或减去存储在展平特征图的相应索引中的值。这重复128次迭代 - 2D权重数组中的行数。for循环用于并行实现32个这样的操作。在此之后的州,
![]()
图6:第一个完全连接的层
第二个完全连接的层
第二完全连接层的结构与第一层完全相同。它接收来自前一层的32长度数组,矩阵使用与前面描述的相同的状态机结构将其与大小为32×10的权重矩阵相乘。输出矩阵是一个10位数组,带有8位条目 - 这些值未进行二值化,以提供有关数字分类的更多信息。
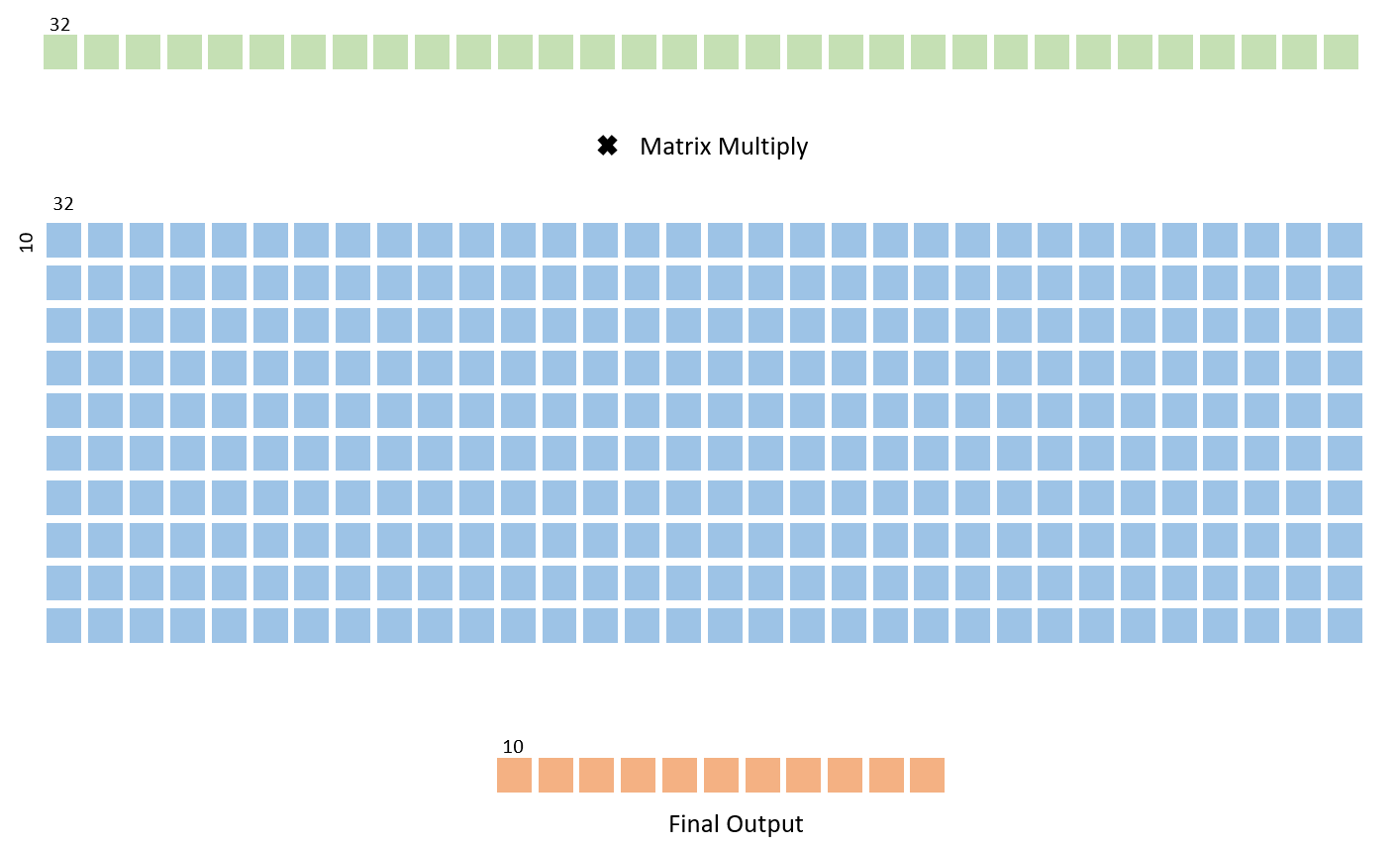
图7:第二个完全连接的层
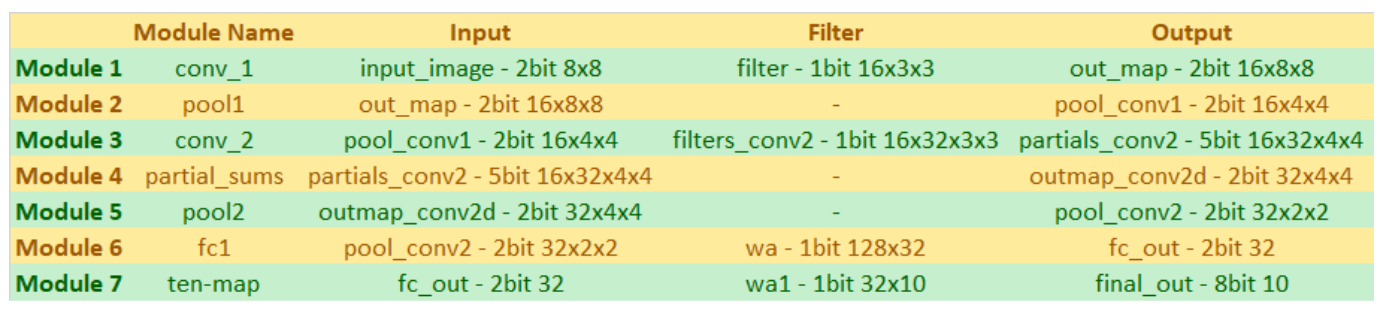
图8:模型摘要
软件设计
二值化神经网络的最终输出是长度为10的阵列。此最终输出数组的给定索引处的值对应于处理的图像是该索引号的图像的可能性。例如,如果索引0处的值是数组中的最小值,则表示处理的图像成为0的可能性最小。同样,如果索引5处的值是数组中的最高值,这意味着BNN推断图像最有可能是数字5.我们通过了这10个最终输出使用8位宽PIO端口从FPGA到HPS的值。HPS然后处理10个最终输出并将数字转换为概率标度以确定图像的最可能的前三个分类。串行控制台上HPS的输出显示在之前的图像中。为了计算概率,我们首先将所有正的最终输出值相加以得到正推断指数的总和。然后可以通过将索引n处的最终输出的值除以正推断索引的总和来计算数字n的概率。
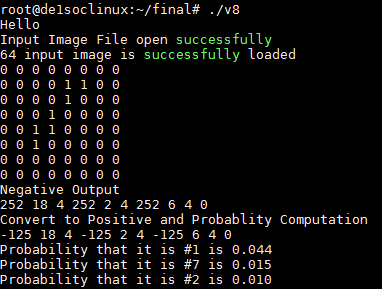
图9:HPS串行控制台输出
Qsys设计
下图显示了我们设计的Qsys实现。PIO端口从HPS连接到轻量级axi主总线,并以不同的存储器地址输出到FPGA架构。Pio_switch是输出信号,我们用它来选择在hps上硬编码的各种输入图像作为BNN的新输入。一旦选择了pio_swich并输出到FPGA,HPS就会将pio_start从低切换到高,以重新启动BNN数字识别计算。在BNN重启时,PN_end设置为低电平,并且只有当BNN完成计算最终输出阵列时,FPGA才会设置为高电平。通过记录复位时间和pio_end变高的时间,我们可以通过开始和结束时间差计算我们的BNN计算时间,我们发现它们大约是4-5us。
在FPGA完成计算之后,使用三个PIO端口(用于时钟信号的pio_hps_image_clk,用于数据信号的pio_out_data和用于芯片选择信号的pio_out_cs)来顺序地从FPGA接收10个最终输出到HPS。芯片选择线通常保持低电平以重置索引。当芯片选择为高时,最终输出阵列的相应索引将在时钟信号的每个上升沿加载到数据信号。在此之后,索引递增。为了开始接收最终输出,HPS将芯片选择拉高,切换时钟信号,然后在数据端口读取并存储该值,从而将最终输出数组的值存储在索引0处。然后重复此过程9时间接收所有最终输出数组数据值。
![]()
图10:Qsys PIO端口
测试
我们在Modelsim上测试了我们设计的初始迭代,并使用了单元测试来确保我们的每个模块都按预期工作。我们实现了每个模块,并传递了已知的输入值和模拟结果,以验证输出是否符合预期。一旦我们为所涉及的所有层完成了这个,我们就开始实例化所有层并将它们相互连接。然后,我们将所有权重值和输入图像设置为已知值,并监控整个网络中的流量。
![]()
图11:Modelsim输出
一旦我们的设计模拟正确,我们将其移到FPGA上并使用LED和PIO端口来查看每层的输出,以确保设计在硬件中执行,就像在模拟中一样。由于Modelsim仅模拟并行执行,因此我们必须使用FPGA上的设计重复所有测试,以实际验证我们的层是否按预期工作。我们发现的一些错误是顺序操作的并行实现,例如累积和导致FPGA上的计算不准确。在Modelsim中,这些模拟正确,因为软件中的执行实际上是顺序的,但实际电路生成时并非如此。
在FPGA上进行调试时,每个层的实现都是通过将输出映射到LED或在通过PIO端口将其发送到HPS后在串行控制台上打印来测试的。将硬件计算值与软件实现的Python模型进行比较,以验证每个层是否按预期运行。虽然调试模型的最有效方法是通过PIO端口传递输出值并在串行控制台上打印输出,但最终我们在FPGA上运行了算术逻辑模块(ALM)。此时,我们不得不切换到板上LED的映射输出,以验证计算的值是否准确。
硬件错误和问题
虽然我们最初希望完全并行地实现设计,但系统的某些元素使这变得不可行。网络的一些组件,例如部分和模块,需要多个周期才能正确操作。对于该模块,必须一个接一个地执行16次加法运算以计算累积和。这16个操作不能并行实现,因此需要几个时钟周期来执行。我们遇到的其他问题是,当连接PIO端口以在FPGA和HPS之间传递数据时以及将FPGA输出映射到电路板上的LED时,电路板上的ALM会反复耗尽。添加端口或LED映射有时会导致实现设计所需的ALM资源大幅跳跃,导致设计不适合电路板。我们通过找到使用较少ALM的变通方法来解决这些问题 - 例如,我们不是从HPS传递权重,而是在Verilog文件中硬编码它们。由于权重在分类期间的任何时候都不会发生变化,因此这对功能没有任何影响。
结果
下图显示了我们最终演示的LCD显示屏。显示前三个计算的概率,以及传递到网络中的合并的8×8输入图像。完整的二值化神经网络能够准确地执行分类图像所需的计算。将每层的输出与软件中相应实现的输出进行比较,以验证正在执行预期的计算。软件精度的预期准确度为33% - 由于硬件模型模拟了软件模型的计算,因此硬件分类器的预期精度也可假设为33%。
![]()
图12:显示输出:数字1
![]()
图13:显示输出:数字5
通过将表示计算已完成的结束信号传递回HPS并测量从HPS发送到FPGA的开始信号到从FPGA发送的结束信号之间的时间来测量软件模型的计算速度。回到HPS。发现该FPGA BNN计算时间约为0.004毫秒或4us。另一方面,在PC上运行的相同BNN的Python实现大约需要44us。此时间测量是通过在y_conv上运行Tensorflow Eval函数所需的持续时间来计算的:y_conv.eval(feed_dict = test_dict),其中y_conv是BNN的最后一个张量层。在1个批量大小中,我们测量处理1个输入所需的时间,大约为64.4ms,我们还测量处理180个输入所需的时间,大约为72.4ms。因为CNN的处理时间是加载权重和计算的总时间,为了提取计算权重的时间的粗略估计,我们使用时差和(72.4ms-64.4ms)/ 180数据= 44us /数据。请注意,我们在四核PC上运行python代码。存在不稳定性来测量时间差和可能导致PC下的时间测量变化的各种因素
资源使用
下表总结了我们设计最终实施所使用的一些不同资源。可以看出,BNN仅使用FPGA上可用总存储器的一小部分,并且使用三元运算符可最大限度地减少对乘法器/ DSP模块的需求。最常用的资源是ALM,但当用于将输出数据传输到HPS,在设计中传达开始和结束信号等的PIO端口不包括在内时,其中一半以上的电路板仍然可用。 。这些结果证实了BNN的低资源需求。
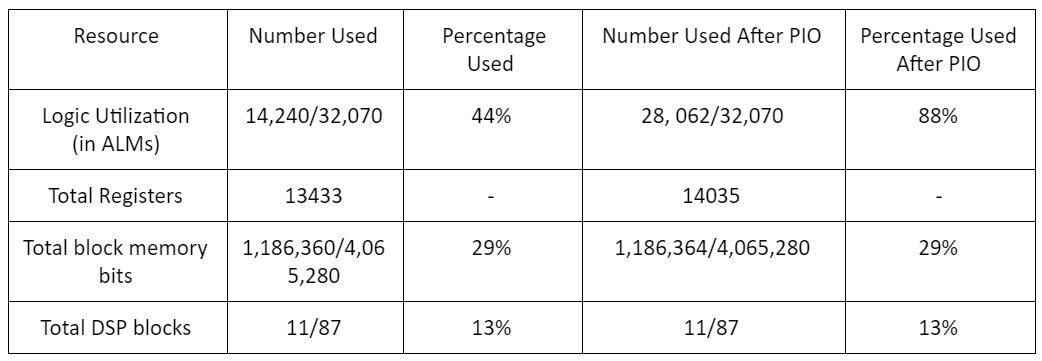
图14:资源使用情况摘要
可用性
当前的设计不是非常灵活,因为输入图像必须硬编码到Verilog代码中才能进行处理。由于权重也是硬编码的,因此对这些权重的任何更改都需要修改和重新编译代码。通过使用PIO端口或SRAM存储器将权重从HPS传输到FPGA,可以使设计更加可配置; 然而,根据我们目前的实现,引入这些元素中的任何一个都会导致设计不适合FPGA。虽然数字分类本身并不是极其广泛适用的任务,但图像分类在今天有许多用途。硬件分类器的加速使其更适合于实时分类任务,其中定时是主要约束。











