







高水平的设计
在高级设计中,我们将使用HPS导入图像并对其进行解码。我们还使用HPS加载VGG16重量。然后我们将它们输入FPGA。FPGA将采用计算部分。经过计算,FPGA会将结果输出到HPS。结果将是图像的特征。HPS将显示通过VGA监控的功能。对于图像输入,我们使用MATLAB对其进行预处理。提取RGB值,然后计算它们的平均值并从原始数据中减去它们。减去数据集意味着用于“居中”数据,因此具有更好的学习速度。在这个项目中,我们采用16:1:7:8的定点格式。在这种格式中,精度可以达到0.00390625,整数部分的范围是-127到127。输入数据在-127到127之间,并且所有权重都相对较小(通常为0.03-0.3)。输入和预训练权重的转换由MATLAB中的sfi函数完成。HPS是FPGA的主要控制。它将发送FPGA的命令和数据,以实现和接收FPGA中结果缓冲区的结果。为了实现预先训练的VGG16模型,我们需要通过命令load_mem加载表示FPGA中三行输入的三个寄存器。然后我们通过命令load_fil将前16个滤波器加载到FPGA中的滤波器寄存器。输入就绪后,卷积计算将对输入文件的前三行执行,并通过命令计算执行前16次过滤。然后我们通过命令getresult从这16个过滤器中读取结果并将它们保存在本地文件中。接下来将加载16个过滤器,我们重复该过程,直到处理完所有过滤器。最后,我们加载一个新行并反复重复所有内容,直到输入文件中的所有行都被所有过滤器相乘。
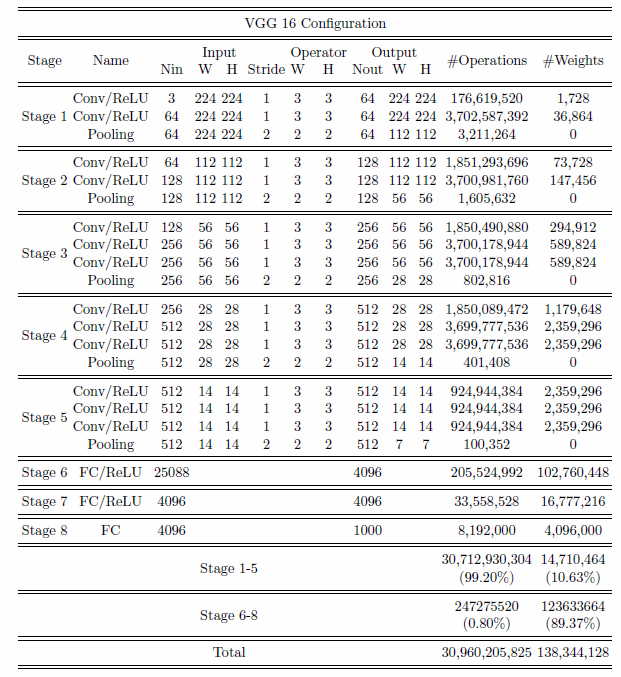
VGG 16神经网络的复杂性(来自[5]作者:李媛媛)
卷积计算
卷积层是CNN中最重要的部分,与整个网络相比,其计算量超过90%。卷积计算公式如下所示:
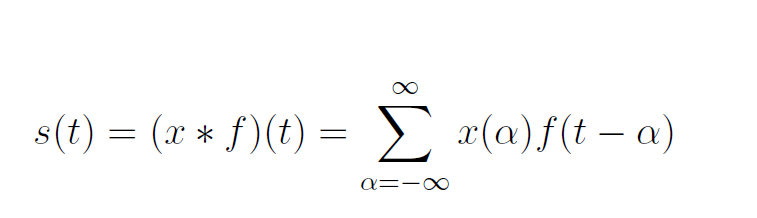
x(t)和f(α)被称为输入和权重函数。输出称为特征映射。对于我们的项目,我们使用了2D空间,过滤器也是2D。我们的卷积层以三个输入和一个输出开始。三个输入表示RGB值。每个输入代表一个通道,每个通道与滤波器相关。然后,bias是一个唯一的标量值,它被添加到每个像素的卷积层输出中。我们得到了VGG16预训练数据集的所有权重和偏差。每个输入与相应的滤波器相乘,求和产生输出结果。下图可以更好地解释卷积计算的工作原理。
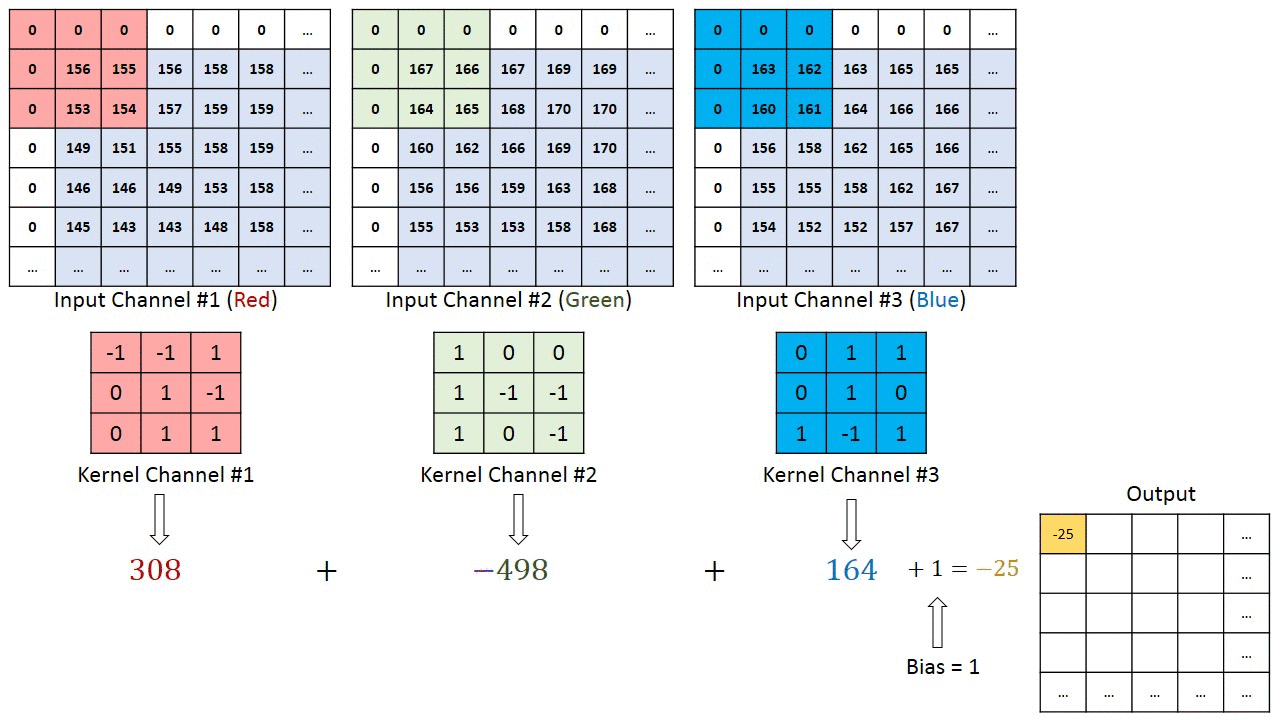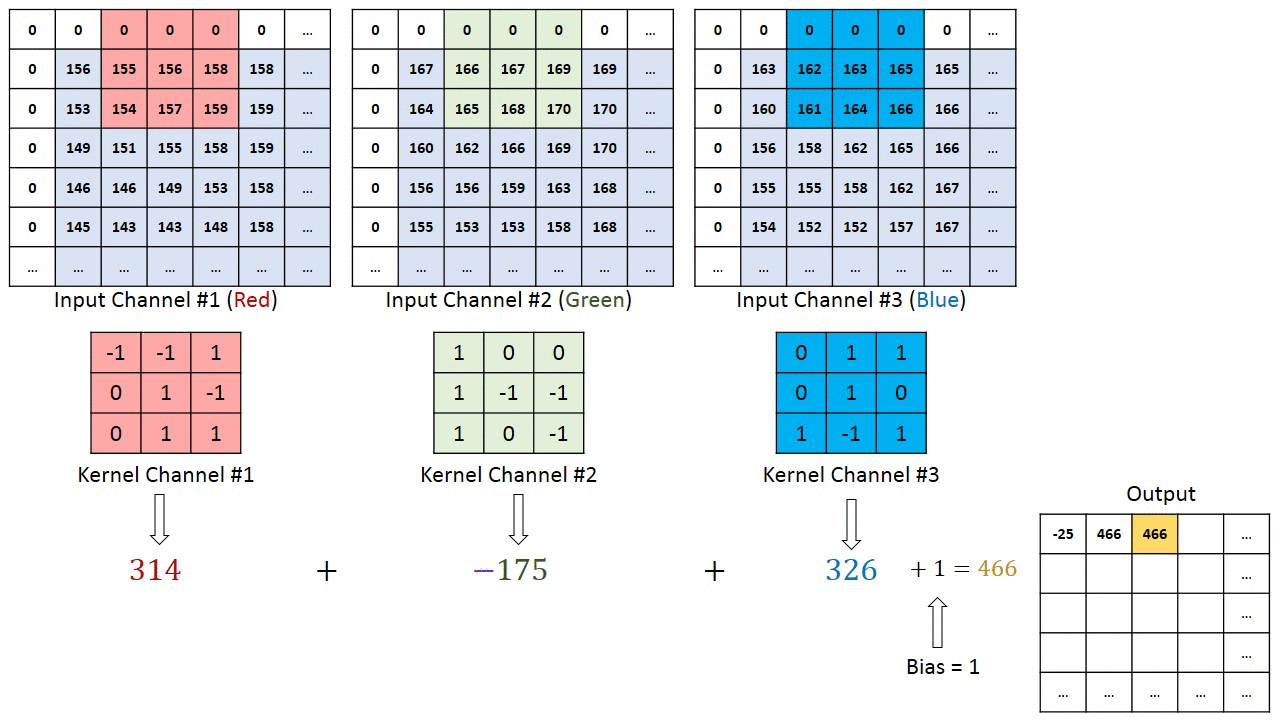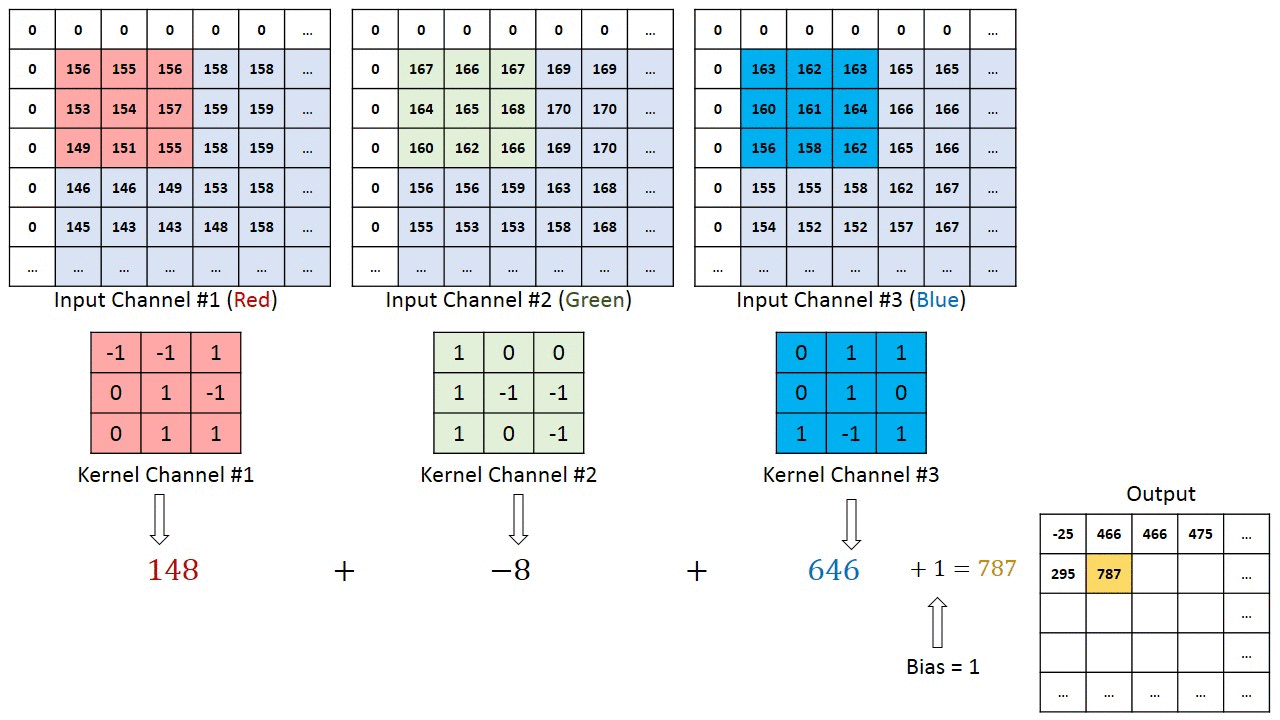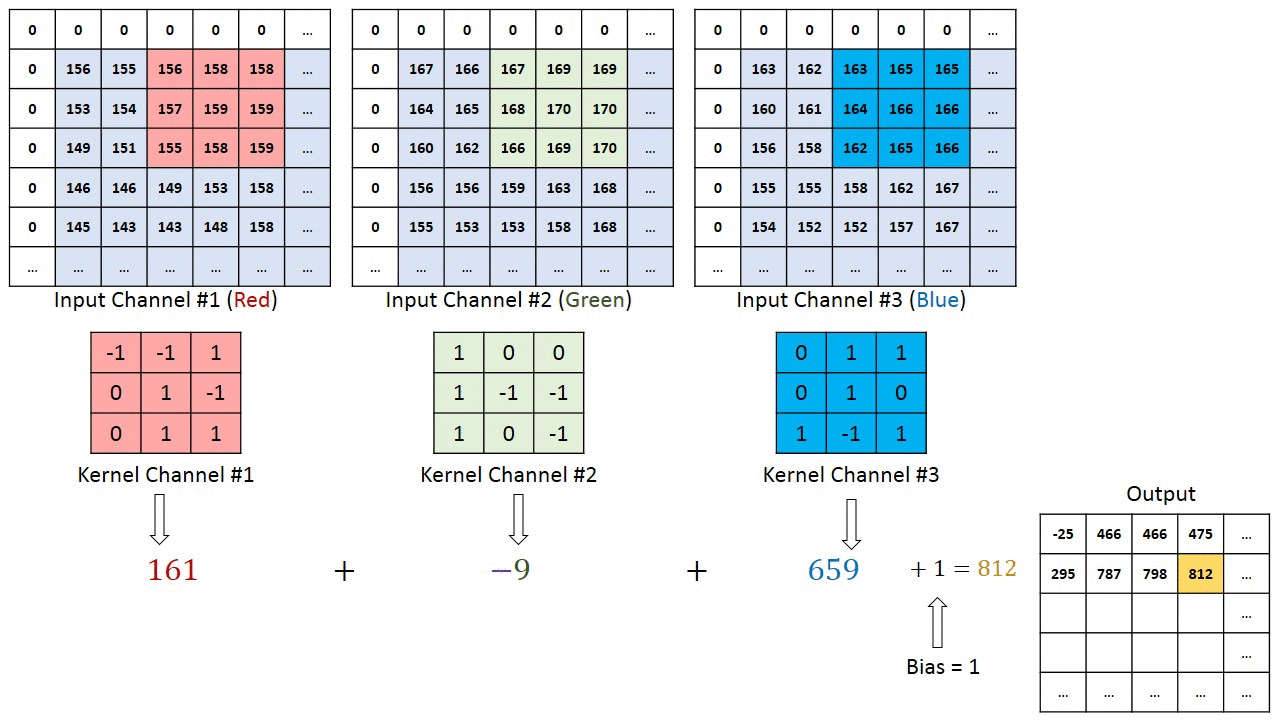
卷积层计算(来自[4]作者:Hadi Kazemi)
汇聚层计算
池化层的功能是压缩卷积特征映射。池化运算符包括最大池和平均池。对于我们的项目,我们使用了max-pooling。我们使用一个图来说明如何最大化池工作,它像一个正常的卷积一样滑动一个窗口,并获得窗口上的最大值作为输出。
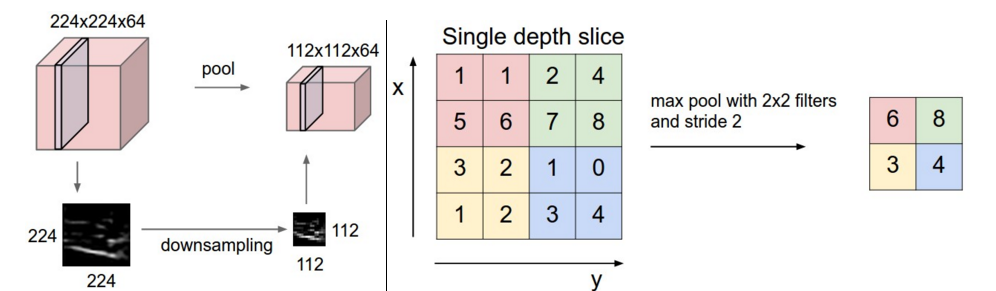
Max pooling(来自[3]作者:Andrej karpathy)
软件设计
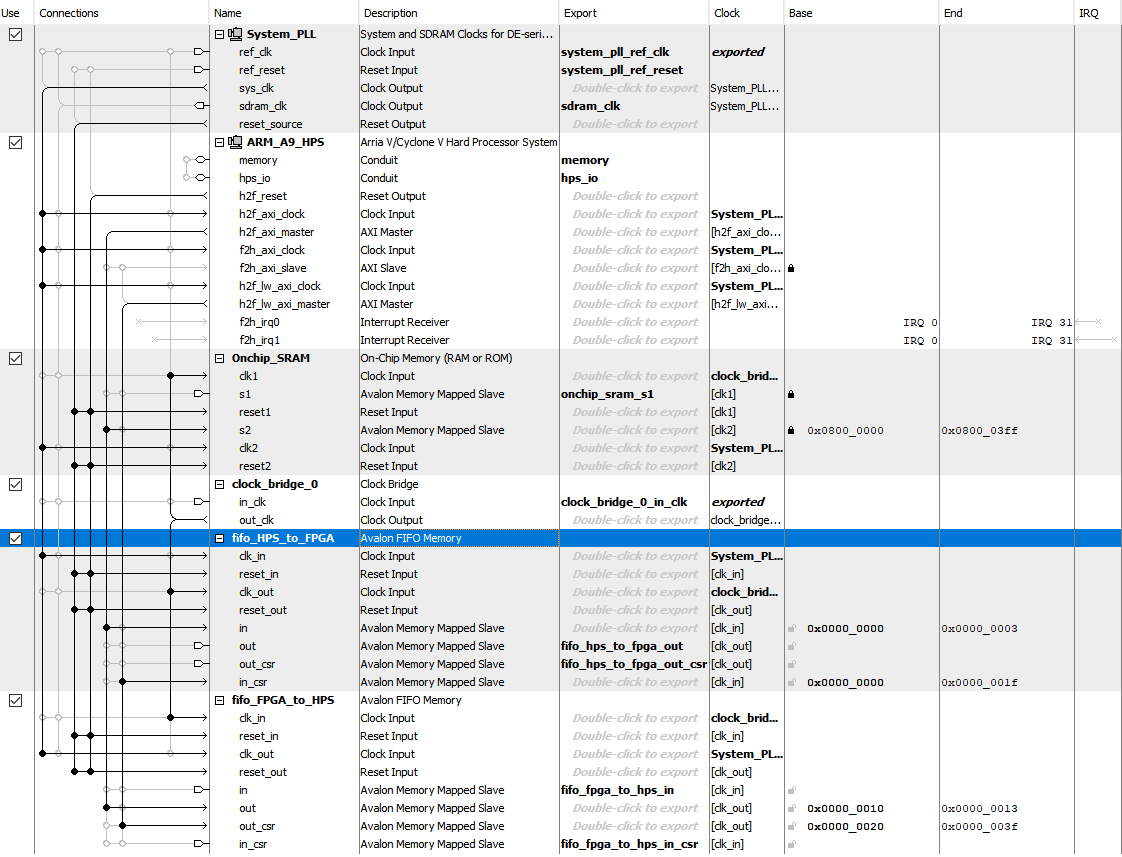
顶级Qsys布局
Verilog设计
FIFO
对于FIFO设计,我们使用来自hackaday的Bruce资源作为HPS和FPGA之间的通信桥梁。在Qsys中,定义了两个双端口FIFO,每个端口都有一个端口连接到HPS总线,另一个端口输出到FPGA架构。我们使用的FIFO深度为256,数据宽度配置为32位。由于我们用于计算的数据是32位,因此每次发送2个数据。对于HPS_to_FPGA FIFO,只要有数据,read_buffer_valid将设置为1,数据将保存在read_buffer中。在我们处理其他步骤中的数据并将read_buffer_valid设置为0之前,不会读取新数据。类似于FPGA_to_HPS,当我们将数据保存到write_buffer并将write_valid设置为1时,FIFO将读取该数据,并将其发送回HPS并将write_valid设置为0以用于下一个输入。

FIFO
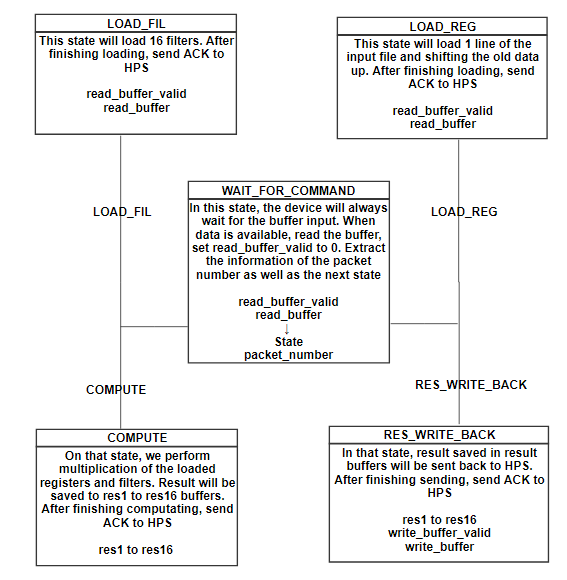
FPGA状态机
WAIT_FOR_COMMAND
在WAIT_FOR_COMMAND状态下,电路板将等待HPS的输入。HPS将生成一个32位命令,前8位表示FPGA应接收的数据包编号,以及下一个状态的类型。在提取这些信息后,FPGA将从下一个时钟切换到新状态。
LOAD_REG
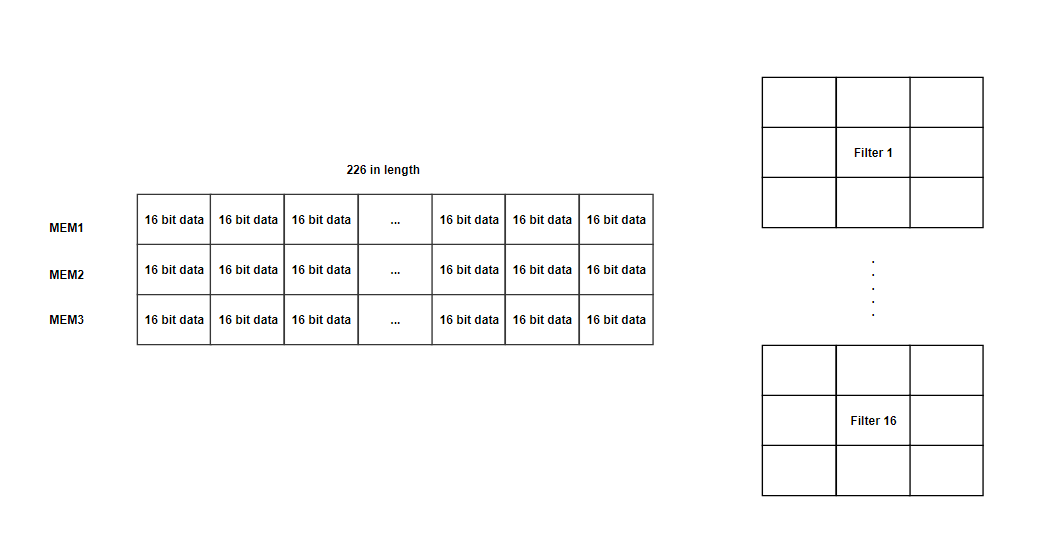
在该状态下,我们有三个寄存器(MEM1,MEM2,MEM3)能够保存226个16位数据。我们主要使用226长度寄存器用于第一级,其具有226x226输入大小(用于填充的额外2位),并且大部分寄存器将不用于以下级。这里不使用M10K和MLAB,因为我们想要一次访问多个数据。由于寄存器的数量非常有限,我们将大输入文件分成几行。在该状态下,每个时钟我们将2个输入数据加载到MEM3并向上移动旧数据。完成加载MEM3(旧数据转移到MEM2和MEM1)后,通过将write_buffer_valid更改为1将ACK(0xffff)信号发送到HPS,并将结果保存到write_buffer。由于滤波器大小为3x3,我们需要加载三条线来启用计算。每次我们用相应的过滤器完成计算,
LOAD_FIL
在该状态下,我们将使用从HPS_to_FPGA的read_buffer读取的权重加载16个滤波器,然后这些16个滤波器将用于在COMPUTE状态下从左到右与加载的寄存器相乘。选择数字16有两个原因:1。每个滤波器将同时执行9次乘法,因此16使得它在一个时钟使用144个乘法器。由于DE1-SOC中有174个乘数,我们确保数量不会超过; 2.过滤器的数量是16的倍数,如64,128,256,512。如果我们使它超过16或更少,我们浪费周期来执行如此繁重的计算。加载16个过滤器后,ACK信号将被发送回HPS并切换回WAIT_FOR_COMMAND状态。
计算
我们在该状态下执行加载的寄存器和过滤器的乘法运算。模块计算用于执行寄存器的计算和过滤,并总结所有9个结果。Genvar用于在always循环之外生成16个计算模块。每个模块有1个滤波器窗口和1个寄存器窗口输入。在每个时钟上,always循环中的COMPUTE状态将引发notein信号以通知计算模块,填充寄存器窗口(3x3)和过滤窗口(3x3)。在接收到notein信号后,计算模块将开始用输入模块进行计算,并将notein信号传递给fixedmul模块,在此模块中执行滤波器和寄存器窗口的乘法运算。从fixedmul生成结果需要一个时钟,并将notein的值作为noteout传递回计算模块。当noteout为1时,计算模块总结来自fixedmul的结果,并将结果和noteout传递给外部。Notein信号从外部传递到计算,到fixedmul,计算到外部。我们这样做的原因是同步结果并将其正确保存在结果缓冲区中。在时钟的每个上升沿,寄存器窗口将向右移位,结果捕获将有2个时钟延迟。当我们将所有数据保存在结果缓冲区中时,ACK信号将被发送回HPS并切换回WAIT_FOR_COMMAND状态。寄存器窗口将向右移动,结果捕获将有2个时钟延迟。当我们将所有数据保存在结果缓冲区中时,ACK信号将被发送回HPS并切换回WAIT_FOR_COMMAND状态。寄存器窗口将向右移动,结果捕获将有2个时钟延迟。当我们将所有数据保存在结果缓冲区中时,ACK信号将被发送回HPS并切换回WAIT_FOR_COMMAND状态。
RES_WRITE_BACK
在COMPUTE状态下,从左到右的三行输入上的16个滤波器的乘法结果被保存在res缓冲器中。在RES_WRITE_BACK状态,来自res缓冲区的数据将通过FIFO发送回HPS。当write_buffer_valid由FIFO设置为0时,我们将两个数据保存到write_buffer并将write_buffer_valid设置为1,表示数据已准备就绪。发送完所有结果后,ACK信号将被发送回HPS并切换回WAIT_FOR_COMMAND状态。
HPS设计
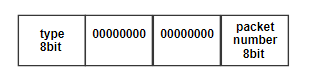
1.Send_command
该函数将为FPGA生成命令,以设置下一个状态以及它应该接收的数据包的数量。数据将以如下格式发送:
2. Load_mem
此函数将获取输入文件指针,需要读取的数字和填充选项。此函数将从输入文件向FPGA发送一行,每次数据包中有2个数据。启用填充后,将在行的前端和末尾添加0数据,如果该行是第一行或最后一行,则将发送整行。在完成发送所有数据后,等待ACK信号并返回指针以读取下一行。
3. Load_filter
该函数将采用输入文件指针,并将16个滤波器的内容发送到FPGA,每个滤波器包含9个权重。在完成发送所有权重后,等待ACK信号并返回指针以读取下一个过滤器。
4.计算
向FPGA发送计算命令并在完成计算时等待ACK信号
5. Getresult
向FPGA发送命令,询问保存在结果缓冲区中的数据。它将接收所有过滤器的输出文件的一行结果。在load_mem,load_filter和compute之后调用它。
6.输出数据处理
对于每个卷积层,我们将有多个输出文本文件。对于每个文件,所有数据都以矩阵格式存储。每个数据是8.8定点格式的16位十六进制数。我们需要将每个十六进制数转换为十进制数。并在将来使用时将新数据输出到文件中。获得这些输出文件后,我们可以将这些文件导入到matlab中以生成功能图像。
测试和结果
我们比较了有和没有FPGA加速器的运行时间和结果。对于未加速的情况,我们将代码纯粹写在C中。数据被处理为浮点用于结果比较和固定点用于速度比较。
结果比较
由于浮点具有最高精度,因此我们将其视为参考,并比较我们的结果与原始结果的距离。正如我们从输出结果中看到的,我们从CNN的第一层提取的特征类似于浮点版本。当我们研究浮点代码生成的数据时,我们发现少量数据的值大于300,超出了我们的16位定点格式的范围,它表明,在FPGA计算中,溢出确实发生了但结果并没有受到太大影响。因此,我们可以得出结论,虽然16位定点会偶尔失去一定程度的精度和溢出,但结果仍然可靠。

示例图片
浮点计算结果

FPGA计算结果
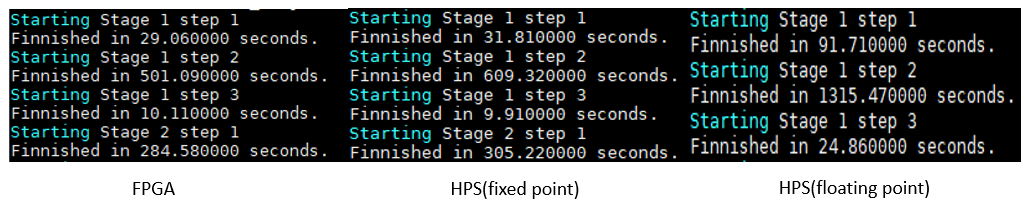
运行时比较
Speed_FPGA> Speed_HPS_Fixed_point >> Speed_HPS_Floating_point
由于其高精度,浮点代码需要最长的运行时间。在HPS定点计算中,我们的FPGA加速器速度提高约12%。阶段1步骤3仅包含HPS计算,因此具有非常相似的结果。并且FPGA加速器在解决涉及重度卷积计算的阶段(如阶段1步骤2)方面表现得更好。卷积计算越多,结果越好。
最后结果
摘要
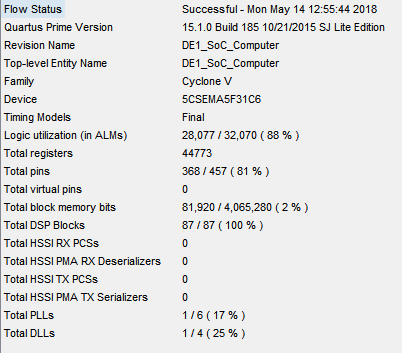
从流状态可以看出,我们利用了所有DSP模块和88%的ALM。事实上,在该项目期间,由于逻辑利用失败,我们失败了很多次。正是通过优化结构,我们使其工作,同时不影响效率。我们克服了三个最难的部分:
1.将数据保存到寄存器中并将其读出:
它看起来很简单,但在代码开发过程中,我们始终无法从FIFO接收数据并将其保存到寄存器中。当时问题在于说谎并不简单,我们所能做的就是让LED闪烁以猜测电路板内发生了什么。在将大件物品分成小块并在ModelSim中模拟它之后,我们使其成功。
2.计算模块执行计算
一个。调试计算模块
一世。要找到这种同步方法需要花费一定的努力。因为我们不能在always循环中调用类似函数的模块,所以我们必须找到一种方法来将输入同步到外部 - 始终模块,并确切地知道结果何时可以读取。
II。滥用电线和注册。Verilog不会为连接生成错误消息,但实际上,数据始终无法从fixedmul和计算模块传递出去。
湾 在浮点和定点之间进行选择。
我们的初始设计使用了16位浮点,但后来我们发现它需要太多的空间和资源。要在FPGA中增加9个结果需要4个时钟,并且为了在HPS侧进行计算,我们需要设计处理乘法和加法的额外函数,这是非常复杂和缓慢的。因此,我们放弃了这种格式,而是使用定点格式。
3.长时间编译
随着项目变得越来越大,调试时间越来越长。通常的编译时间是20分钟来调试一个小东西。
FPGA结果
结论
我们的系统专为卷积计算而设计。它不仅限于VGG16,还可用于执行所有CNN结构的计算。该项目的主要目标是证明我们的想法,即FPGA可用于解决卷积计算,并可加速整个过程。
结果表明我们的FPGA确实略微加速了这个过程。虽然加速度并不显着,但仍有很大的空间可以改进。在这个设计中,我们没有改变FIFO的原始设计,我们保持字宽为32位。最大字宽为256位,这意味着我们可以同时发送16个数据而不是2个。 ,我们使用的时钟是最慢的,以确保不会弄乱系统的其余部分。CLOCK_50仅是最快时钟的1/16,并且比HPS和FPGA之间的通信以及其他计算慢。因此,为了更好地提高效率,我们首先将两个FIFO的字宽增加到256位,这比我们当前的设计快8倍。然后,我们将使用更快的时钟。
FPGA CNN解算器的瓶颈在于存储器的限制。由于无法在电路板上保存所有数据,因此我们必须在HPS和FPGA之间移动数据,并且大部分时间都丢失了。DE1-SOC板是执行FPGA计算的不错选择,我们试图充分利用它。事实上,目前没有专门用于CNN加速的FPGA的良好结构。该项目使我们能够很好地了解未来的FPGA CNN加速器是什么样的,以及处理数据的可能方式。
本文摘自:http://people.ece.cornell.edu/land/courses/ece5760/FinalProjects/s2018/yr233_pq32/yr233_pq32/yr233_pq32/index.html#











